





MLflow is a platform to track experimentation, reproducibility, deployment of machine learning models. On the experimentation phase, mlflow facilitates the versioning of your models. It allows you to save not only the models but also metrics, parameters and datasets. For a quick introduction on mlflow, I found this tutorial and that tutorial to be very helpful.
Say that, to create a model, you standardized a data set using some scaler.
scaler = StandardScaler()
scaler = scaler.fit(X_train)
To make predictions on a new data set using this model, you will need not only the model but also the scaler. The scaler can be saved as a pickel object, using the package pickel.
#save the scaler locally using the package pickel
import pickel
pickel.dump(scaler, open('scaler.pkl', 'wb'))
# save the scaler alongside the model under your mlflow experiment
with mlflow.start_run():
mlflow.sklearn.log_model(model_object, 'model’)
mlflow.log_artifact('scaler.pkl')
On the databricks UI, a quick glance at the experiment’s latest run shows you both the model and the scaler.
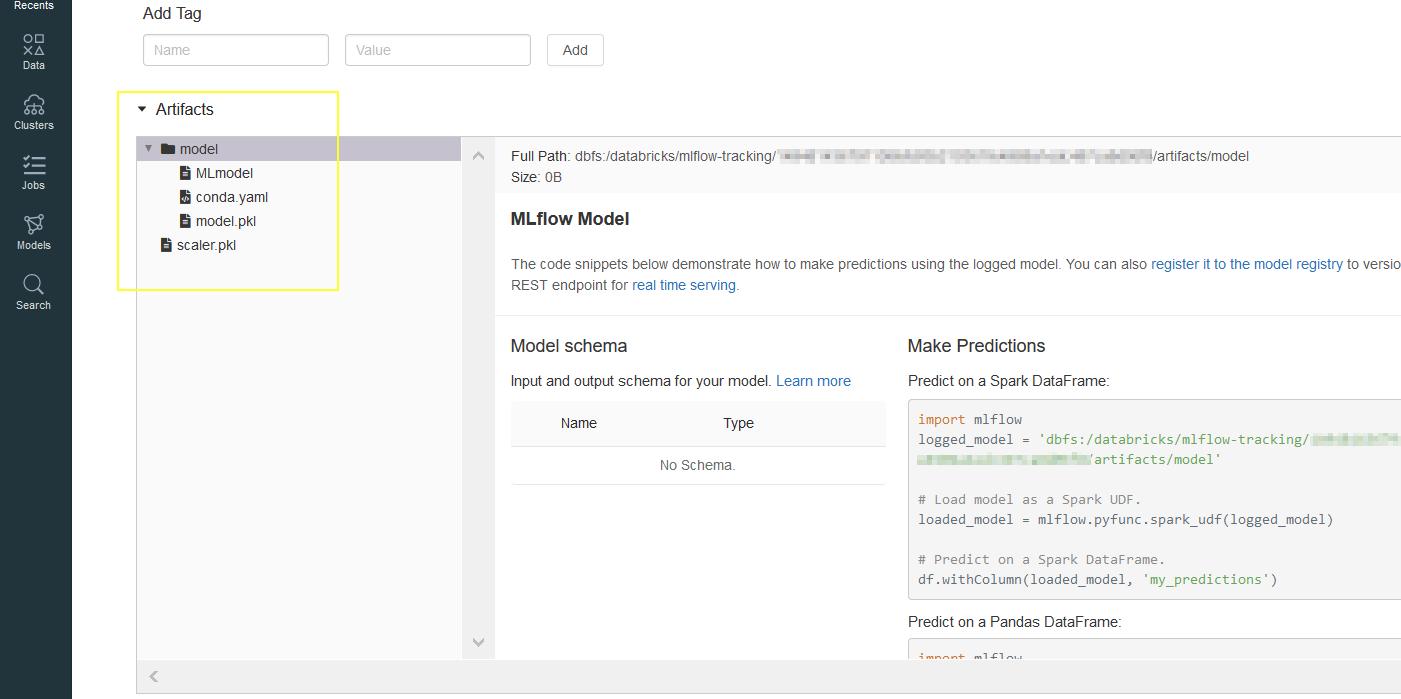
To retrieve the model, we use the function load_model().
# load model saved under run id '124bf7c43bdf4733a0a17c5d4435da71'
run_id = '124bf7c43bdf4733a0a17c5d4435da71'
model_uri = 'runs:/' + run_id + '/logisticRegr'
model = mlflow.sklearn.load_model(model_uri = model_uri)
To retrieve the scaler, we use the function download_artifacts(), as shown in the documentation.
client = mlflow.tracking.MlflowClient()
local_dir = "/tmp/artifact_downloads"
if not os.path.exists(local_dir):
os.mkdir(local_dir)
local_path = client.download_artifacts('124bf7c43bdf4733a0a17c5d4435da71', '', local_dir)
scaler = open('/tmp/artifact_downloads/scaler.pkl', 'rb')
The same procedure can be applied to retrieve any metric, parameter or data set.



{kind=link}