




When running into errors using python, I often resource to Stack Overflow. To my surprise, many analysts post their questions using the actual dataset that causes their error, which sometimes is sensitive data.
As an analyst, it is important to never share client data over the web. For this reason, having a script that creates a quick sample dataset for such scenarios comes in handy. More often than not, we would like a pandas data frame reflecting the data types that analysts are often dealing with.
The following code is a simple way to get your sample dataset going. Start by creating NumPy arrays containing randomly generated data. Using the module np.random, we are able to simulate various data types.
import pandas as pd
import numpy as np
# make the example reproducible by setting a seed
np.random.seed(10)
# dependent variable, if a sale occurs
if_sale = np.random.binomial(n=1,
p=0.1,
size=100)
# numerical feature such clicks
clicks = np.floor(
np.random.exponential(scale=10,
size=100)).astype(int)
# float feature like costs
costs = np.round(np.random.normal(loc=120, scale=10, size=100), 2)
# float feature like views
views = np.round(np.random.normal(loc=1000, scale=50, size=100),0).astype(int)
# categorical feature
import string
platform = np.random.choice(
list(string.ascii_lowercase[:4]),
size=100)
Group all arrays into a dictionary and convert into a pandas data frame.
dict_arrays = {'if_sale': if_sale,
'clicks': clicks,
'platform': platform,
'costs': costs,
'views': views}
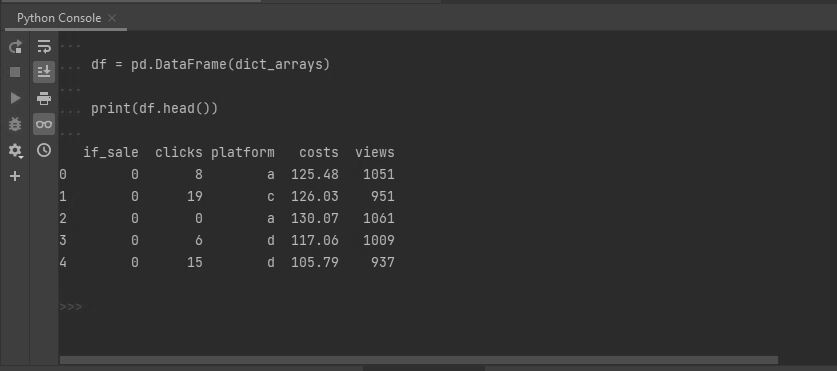
df = pd.DataFrame(dict_arrays)
print(df.head())
The whole script can be found in GitHub.



{kind=link}