




When building a model, I often perform scaling and hot-encoding variables while preprocessing data. It is a part of the process I dislike because I never find a consistent, elegant way to do it and replicate it.
Recently, I ran into the class DataFrameMapper(), which improves this preprocessing for me. This approach is still error prone, as the mapping must be done manually. However, it is an approach I find simple and consistent when dealing with a few dozen independent variables.
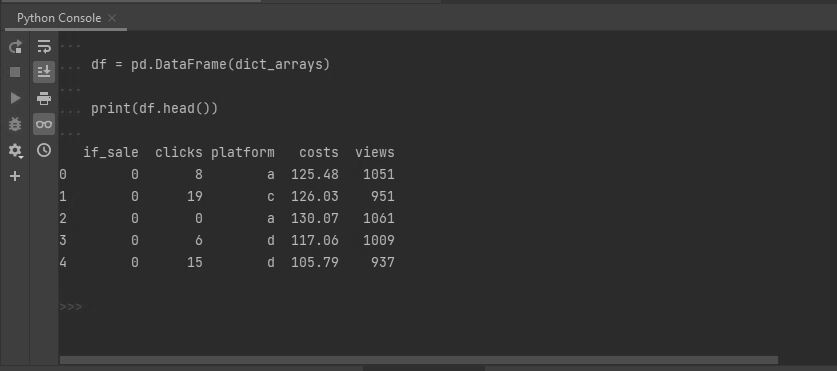
To begin, assume we have a pandas data frame, df, of the form
print(df.head())
if_sale clicks platform costs views
0 0 8 a 125.48 1051
1 0 19 c 126.03 951
2 0 0 a 130.07 1061
3 0 6 d 117.06 1009
4 0 15 d 105.79 937
where if_sale is the dependent variable, and the rest are independent variables. As it is often done, perform the train-and-test split
# separate dependent and independent variables
X=df[df.columns[1:].to_list()] # Independent
y=df[[df.columns[0]]] # dependent
# Split dataset into training set and test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
Next, define which independent variables will be scaled and which will be hot-enconded. In an tuple, pair those variables to be scaled and hot-endonced with the preprocessing classes StandardScaler() and LabelBinarizer() respectively (or any other appropriate scaling of your choice)
# From the dependent variables, define what is going to be scaled and hot-encoded
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelBinarizer
column_tuples = [
(['clicks'], StandardScaler()),
(['platform'], LabelBinarizer()),
(['costs'], StandardScaler()),
(['views'], StandardScaler())
]
Finally, instantiate the mapper class, fit and transform the data frames.
# Create a data frame mapper
from sklearn_pandas import DataFrameMapper
mapper = DataFrameMapper(column_tuples, df_out=True)
# Transform X_train according to X_train
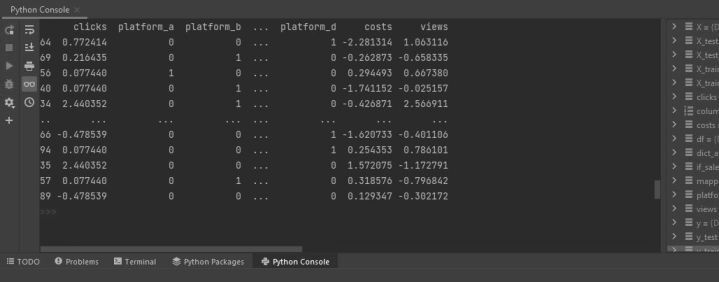
X_train_processed = mapper.fit_transform(X_train)
# Transform X_test according to X_train
X_test_processed = mapper.transform(X_train)
As always, beware to fit and transform the X_train according to itself, and to transform (not to fit) the X_test according to the X_train. Treat test data as new data. Always.
For more on DataFrameMapper(), you can refer to the documentation here. The script can be found in GitHub.



){kind=link}