





In dbt, whenever we create models, tests, seeds, and snapshots, we create nodes. The order in which those nodes are run is called a DAG (Directed Acyclic Graph). A DAG is nothing more than a step-by-step plan on when and under what conditions to execute the nodes. When we run the command dbt build, each node represents a model to be run, a test to be tested, a seed to be loaded, or a snapshot to be taken.
When something goes wrong with running one of the nodes, dbt will decide to skip nodes downstream of the DAG. In the dbt context, skipping a node implies that the node will be acknowledged in the run results, yet it will not be executed, and hence no resources will be spent on it. Understanding which nodes on the DAG will be skipped under what circumstances is important as it will help us understand resource consumption in our data warehouse.
Let’s work with three scenarios departing from a basic DAG. Let’s consider a DAG involving the following nodes:
model_alpha: a model creating a table, based on sourcemy_source_tabletest_alpha: a test ofmodel_alpha, with default severityerrorseed_beta: a CSV file loaded as a seedmodel_beta: a model creating a table, it referencesmodel_alphaandseed_betamodel_gamma: a model creating a table, it referencesmodel_betasnapshot_gamma: a snapshot ofmodel_gamma
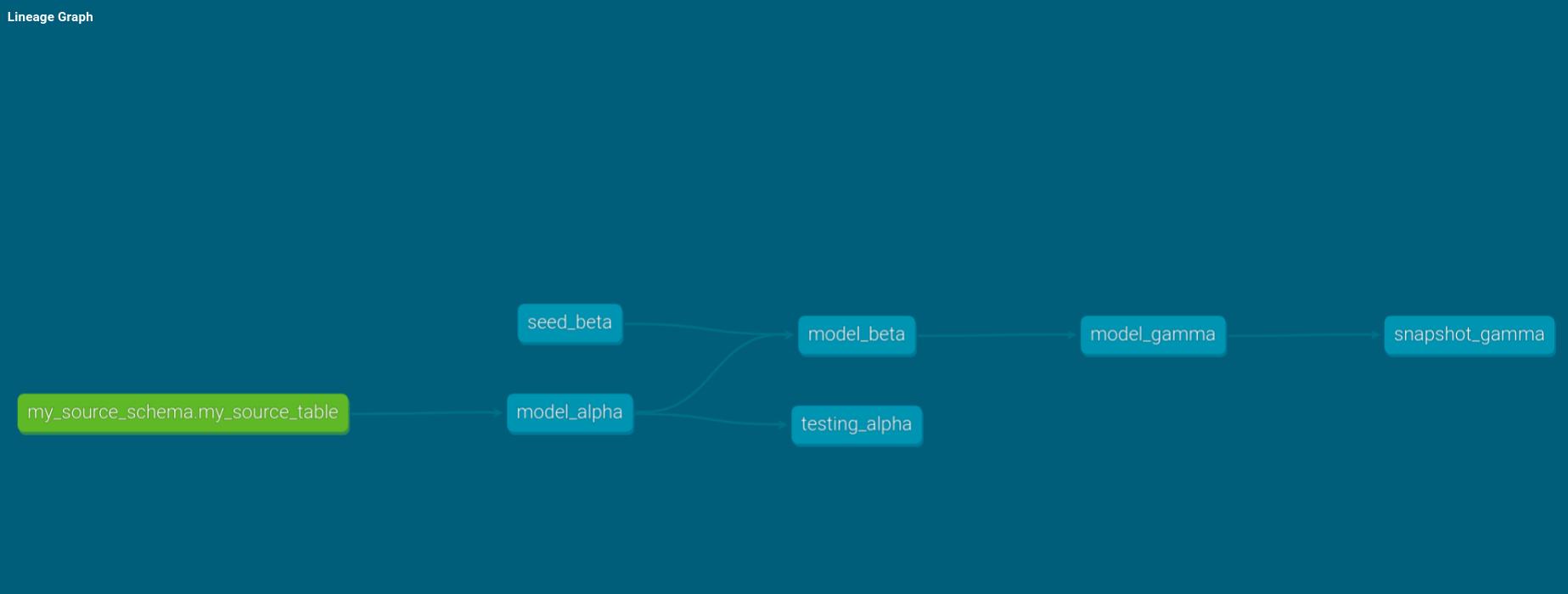
Moreover, let’s assume we work on only one thread. When we build such a DAG, we see results containing six nodes, one for each of the tasks above. When we first run dbt build on our project, we obtain the following results:
The first thing to note is that, even though seed_beta is used by model_beta, it gets loaded after running model_alpha but before testing_alpha.
what happens when testing_alpha fails?
For our first scenario, let’s modify testing_alpha so that it fails.
In order for a test to fail, the test must have taken place. Then, when testing_alpha fails, we know that at least model_alpha was materialized successfully.
Consequently, the remaining models and snapshot are skipped. No resources were devoted to these nodes. However, notice that seed_beta still runs successfully. This is because, as noted previously, seed_beta is set to run before testing_alpha.
what happens when testing_alpha_alt fails?
Let’s now include a second singular test on alpha, testing_alpha_alt. Now we have seven nodes and an updated DAG accordingly.
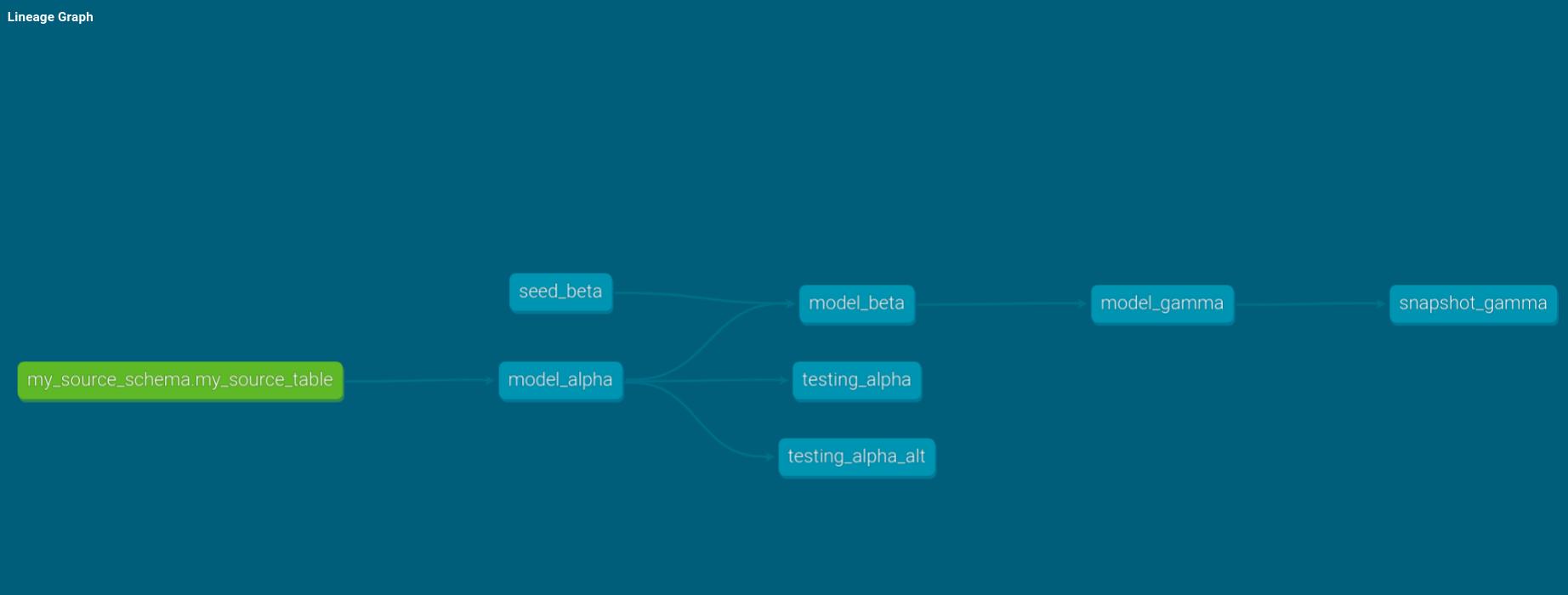
When we build our dbt project, we obtain the following results:
As expected, we know model_alpha must have run successfully.
The most remarkable result from this scenario is that, even though testing_alpha is set to fail, testing_alpha_alt still takes place. Regardless of the type of test, whether generic or singular, if the model is materialized successfully, all tests associated with the model will be carried out.
It is worth mentioning that this behavior will persist even when we include the --fail-fast flag.
what happens when model_alpha errs?
For our last scenario, let’s include a division-by-zero error in model_alpha. After building our project, we obtain the following results:
In this case, we observe that, effectively, model_alpha shows an error and fails to materialize. For this reason, not only does dbt skip the downstream models and snapshot, but it also skips the tests associated with model_alpha.
From this simple DAG, we can conclude that if a model fails testing, its downstream models and snapshots will be skipped. Seeds will still be seeded, however. Moreover, we can conclude that if one of multiple tests fails, the same behavior follows, but the rest of the tests associated with the model will be carried out. Finally, if a model fails to materialize as a table, its associated tests will be skipped as well. Happy querying.






{kind=link}