





Now that Azure Batch and Azure Storage are linked to Azure Data Factory (ADF), let’s create a pipeline:
-
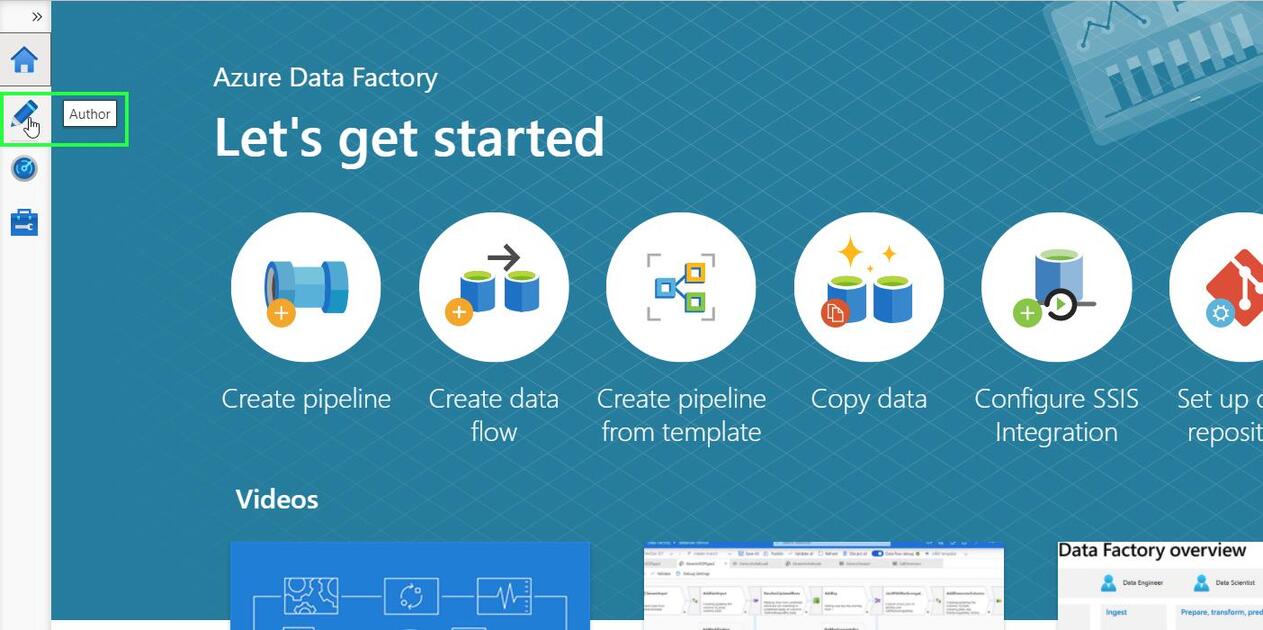
From ADF Home, click on Author
-
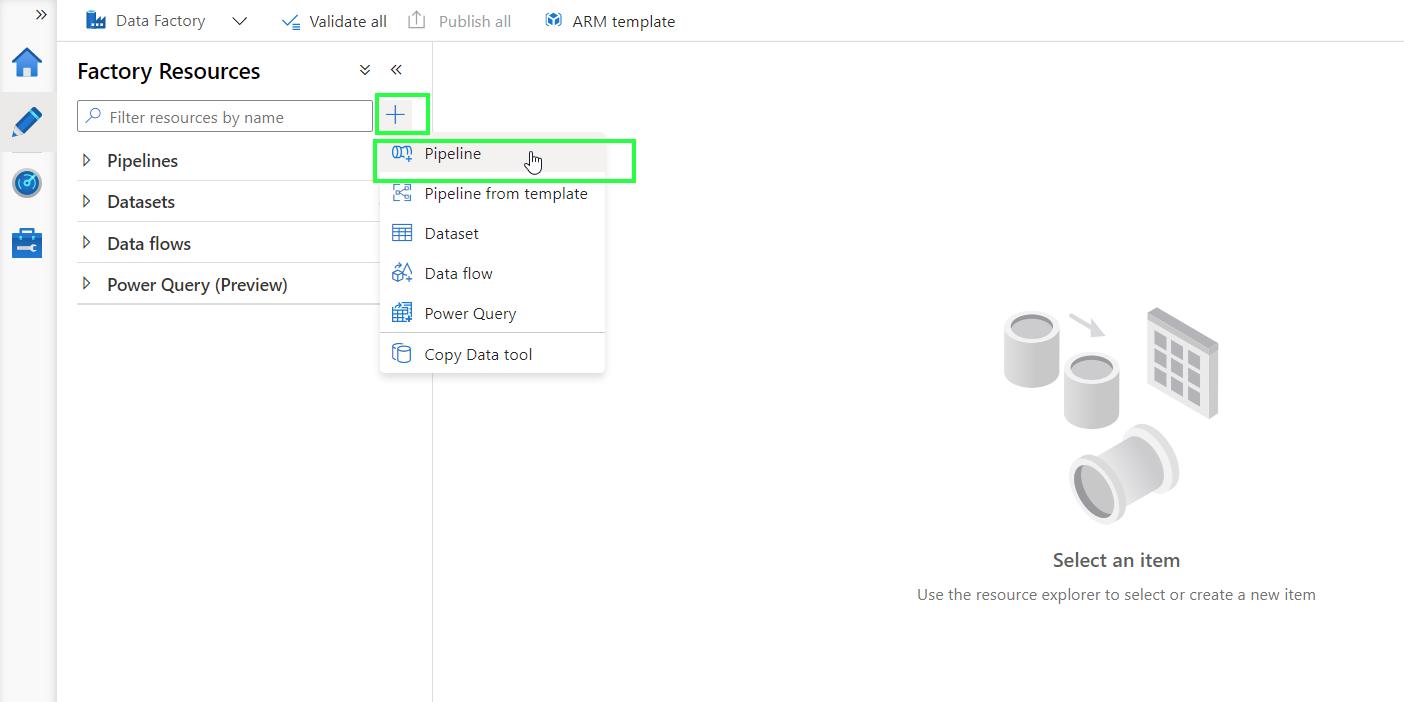
Add a new pipeline by clicking on + > Pipeline
-
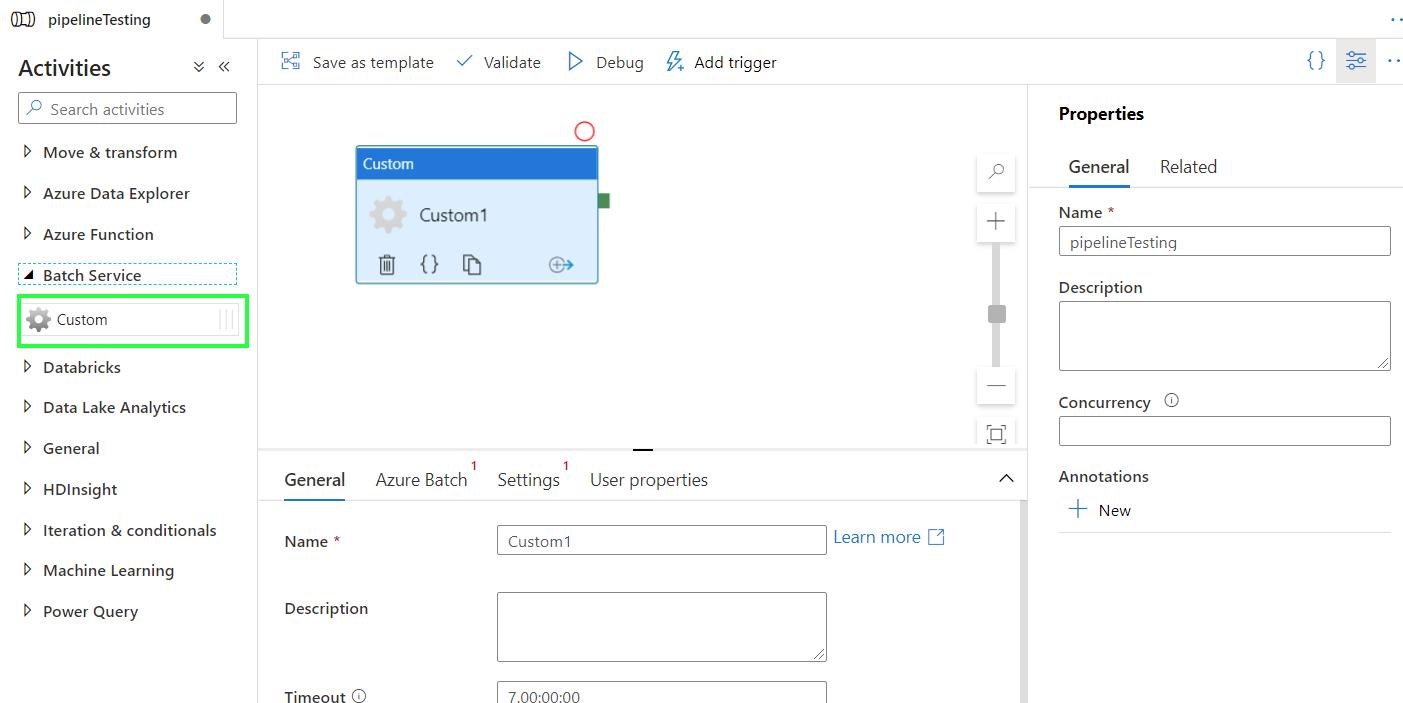
Name your pipeline. Go to Activities > Batch Service and drag the Custom activity into your pipeline
-
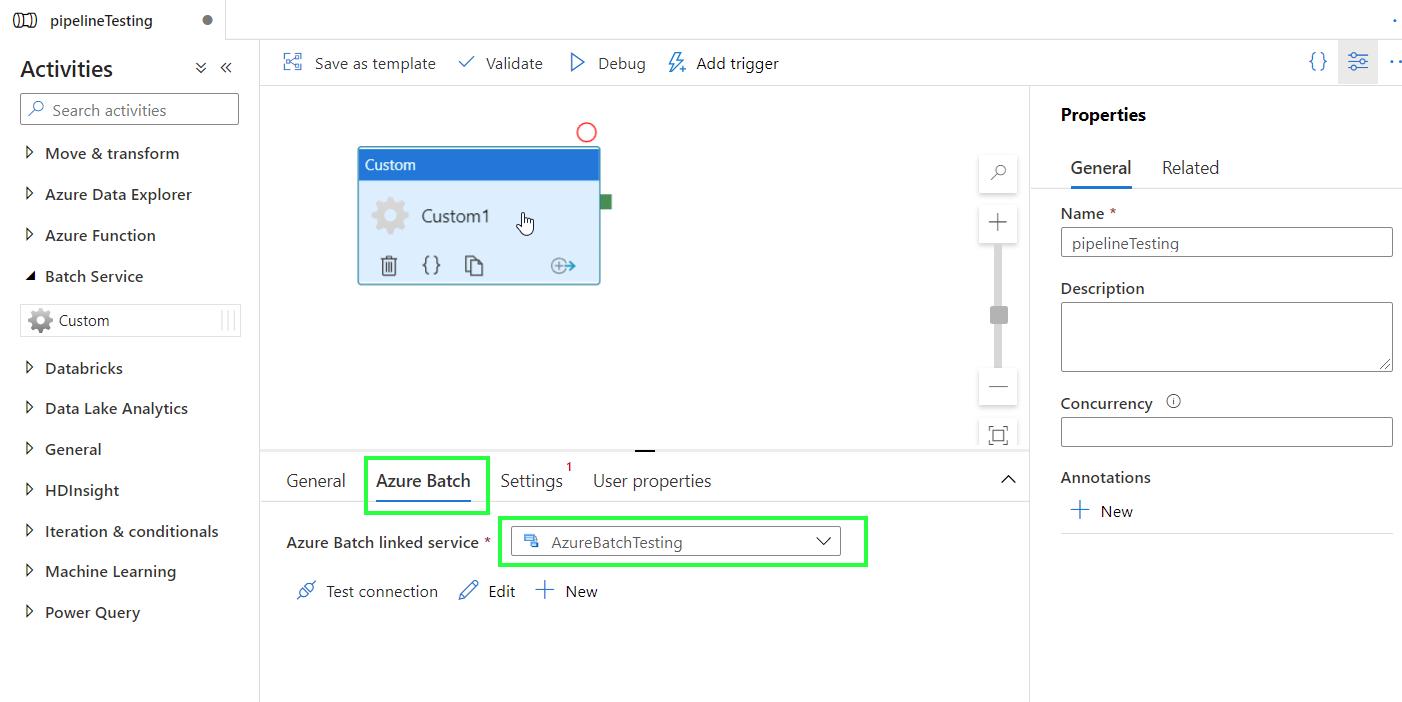
Click on the Custom activity box and go to Azure Batch. From the drop-down menu, select the linked service to your batch account.
-
Now go to Settings. The Command box acts as the terminal window. Here you type the command to be executed during the pipeline run. In our example, the command is
python helloWorld.py(for R scripts,Rscript helloWorld.R)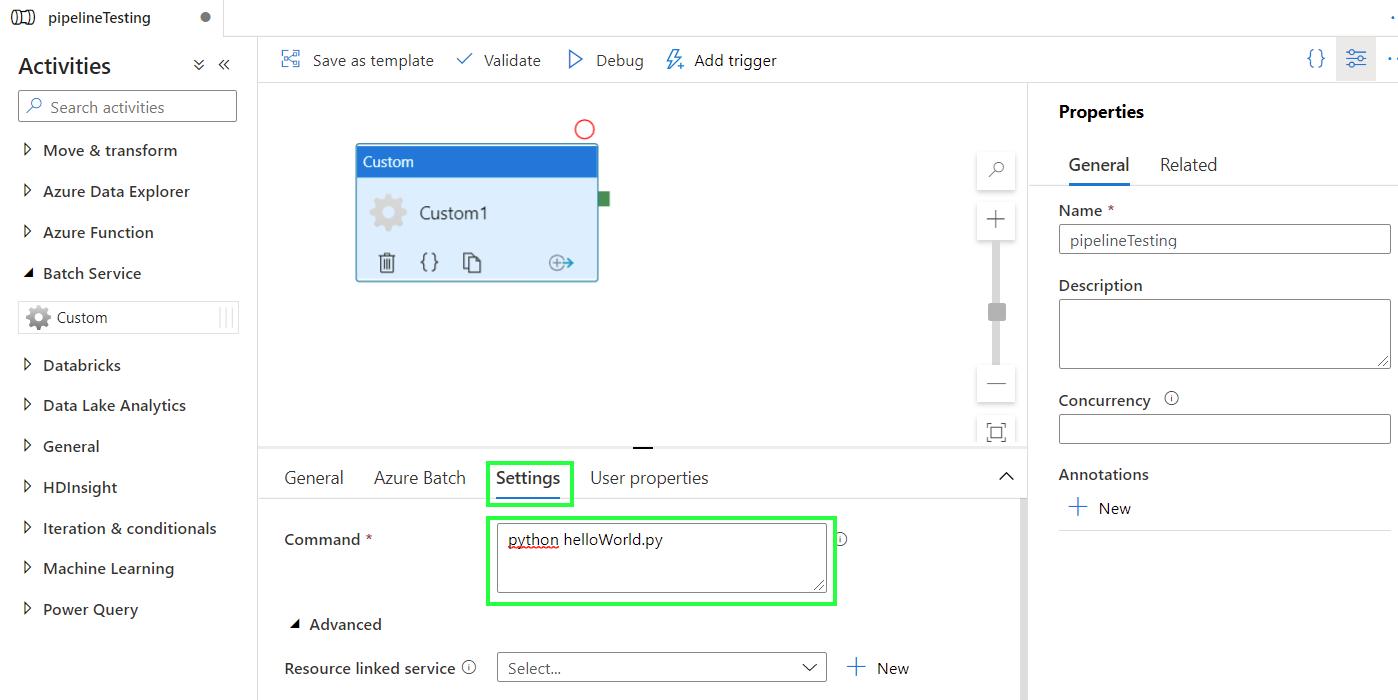
-
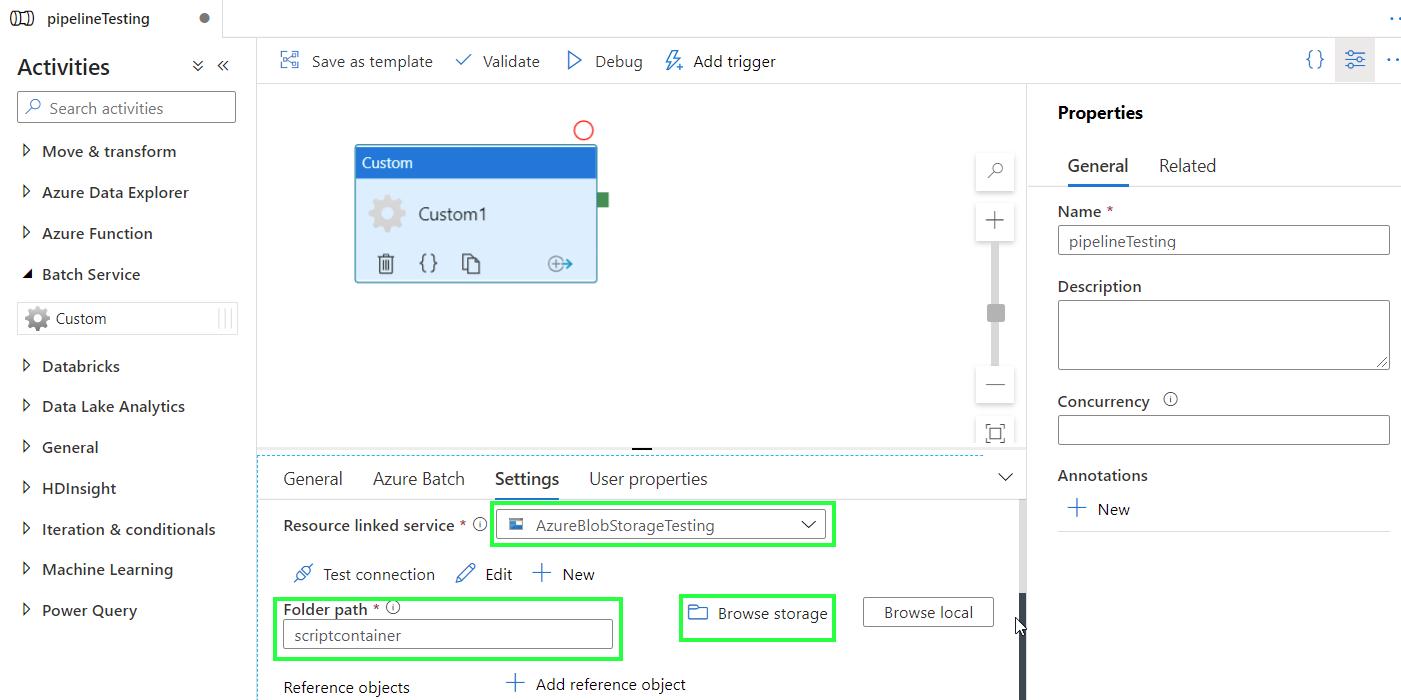
From the drop-down menu Resource linked service, select the linked service to your storage account. Click on Browse Storage and find the script container where helloWorld.py is located.
-
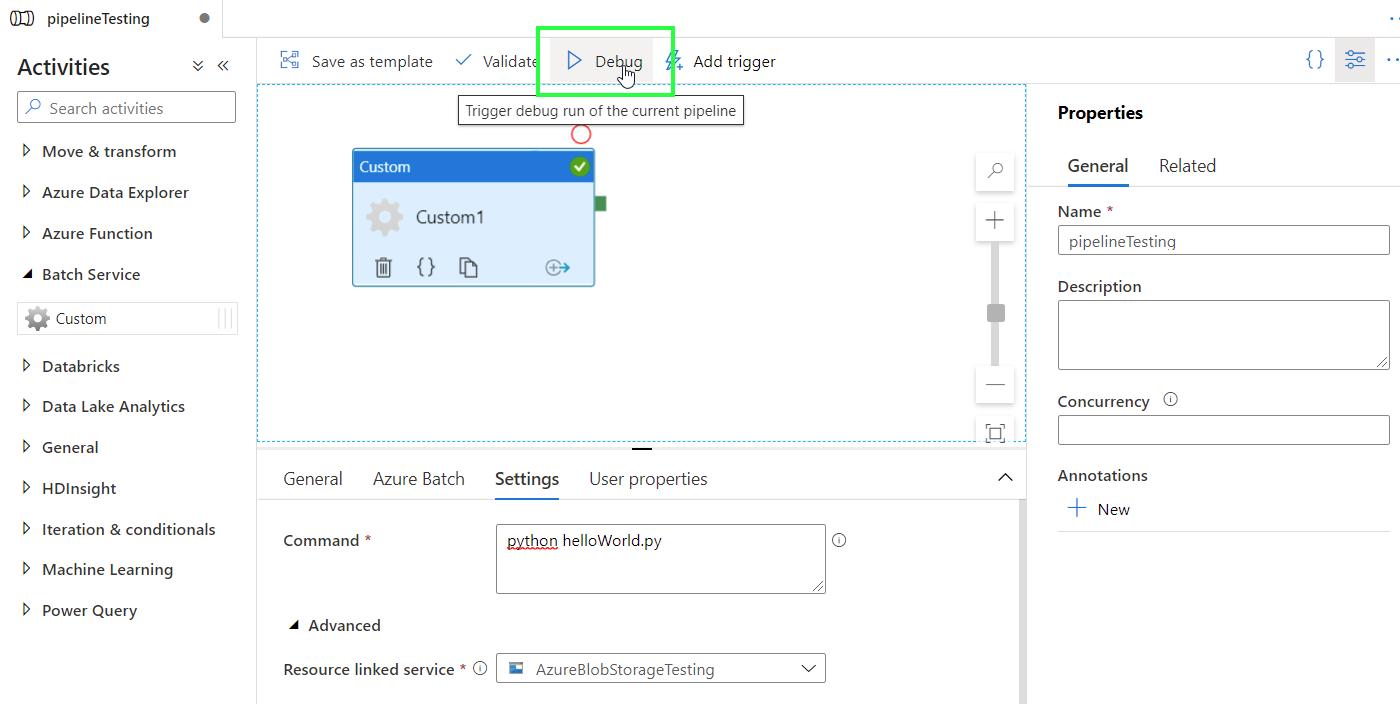
Test the pipeline by clicking on Debug
-
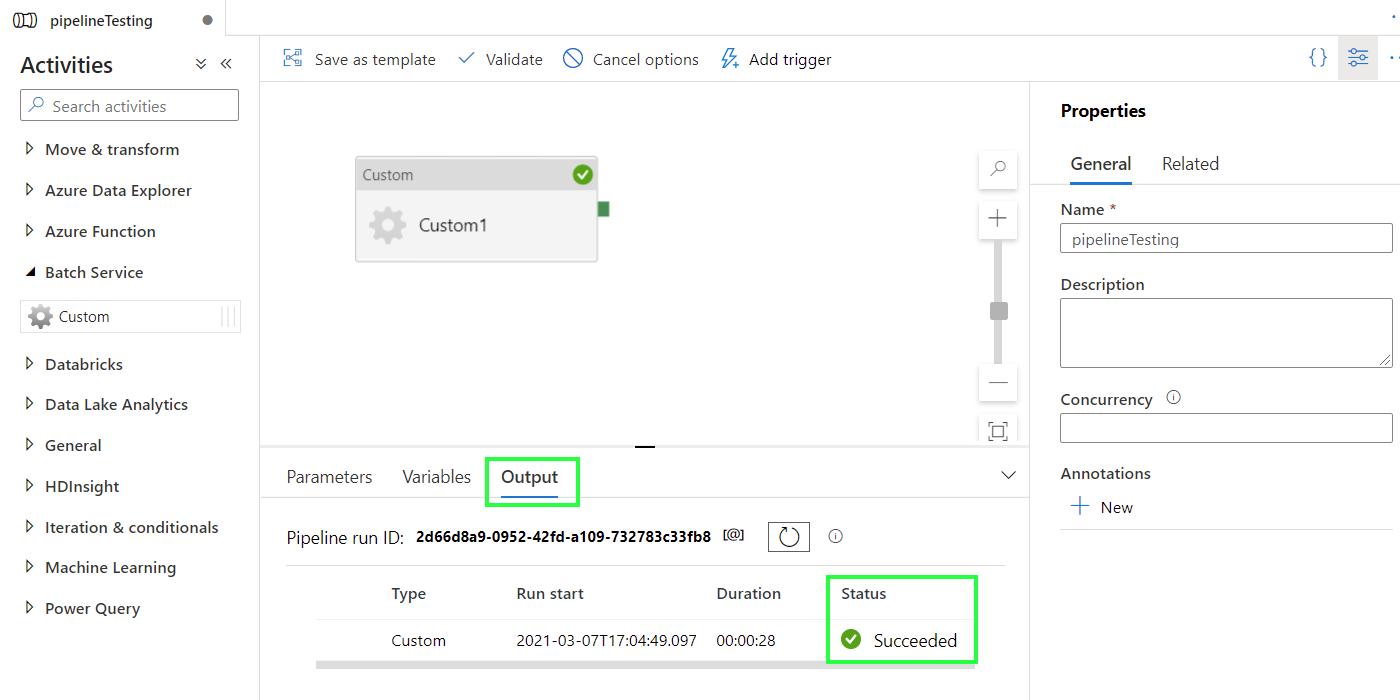
Check the status of the run in Output > Status
-
All run results are saved in the script container. Navigate back to the storage account main site, and go to Blob service > Containers. A new container adfjobs has been created. Click on the container
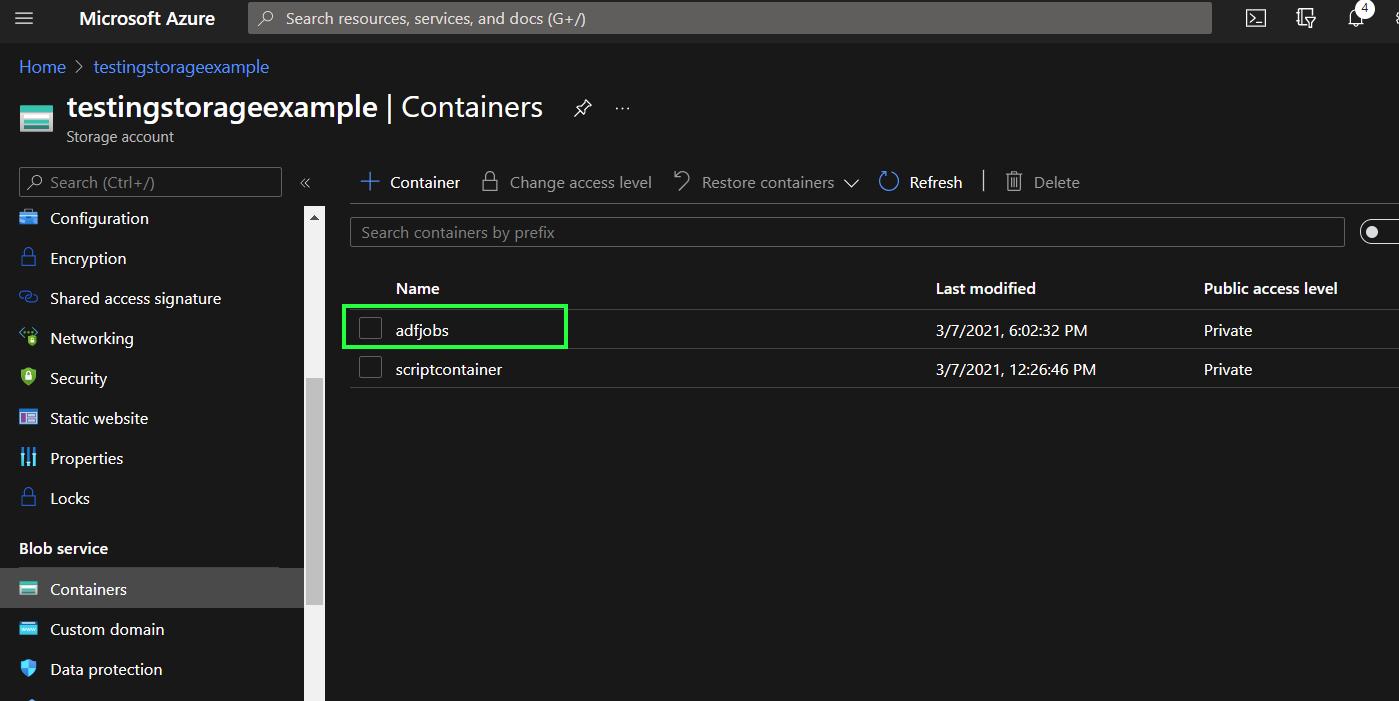
-
In this container, you will find folders with output results from all runs related to this storage account/container. Click on the folder of any run and then click on the subfolder Output
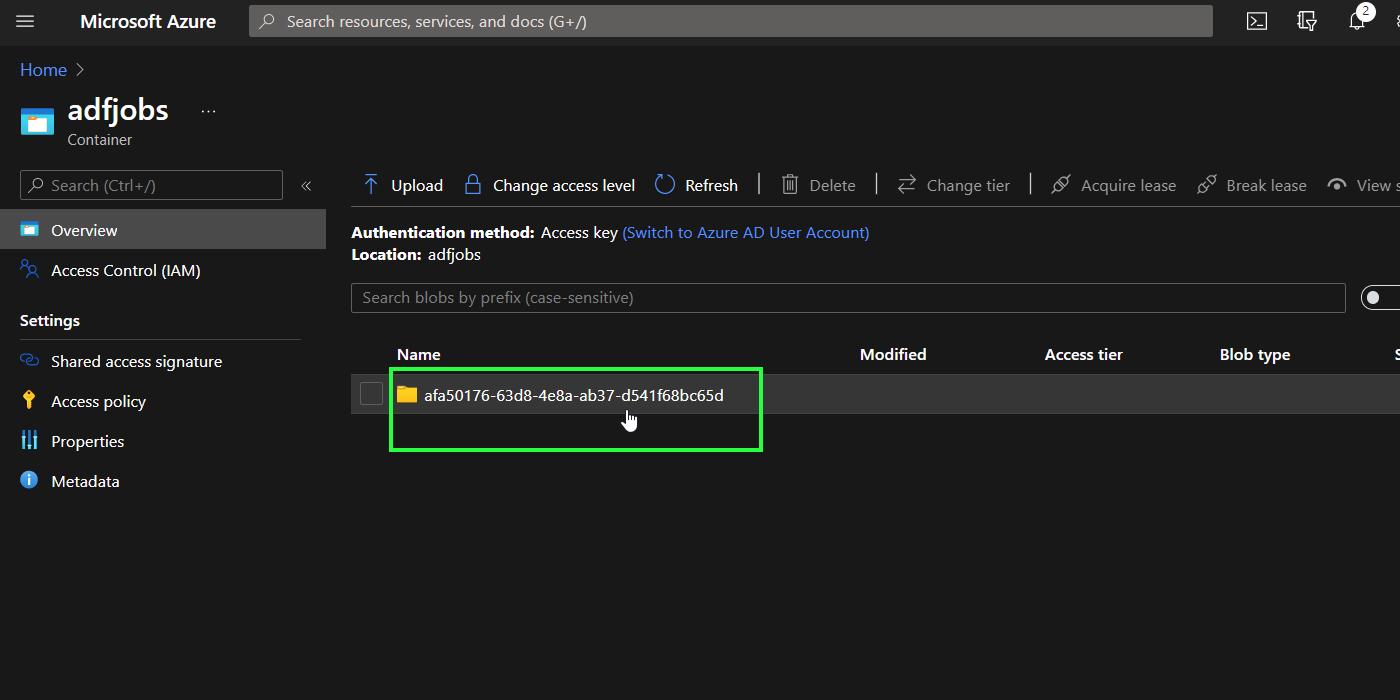
-
You will find the files stderr.txt and stdout.txt which contain information about errors and output respectively. To inspect the output of the run, right click on stdout.txt and then select View/edit
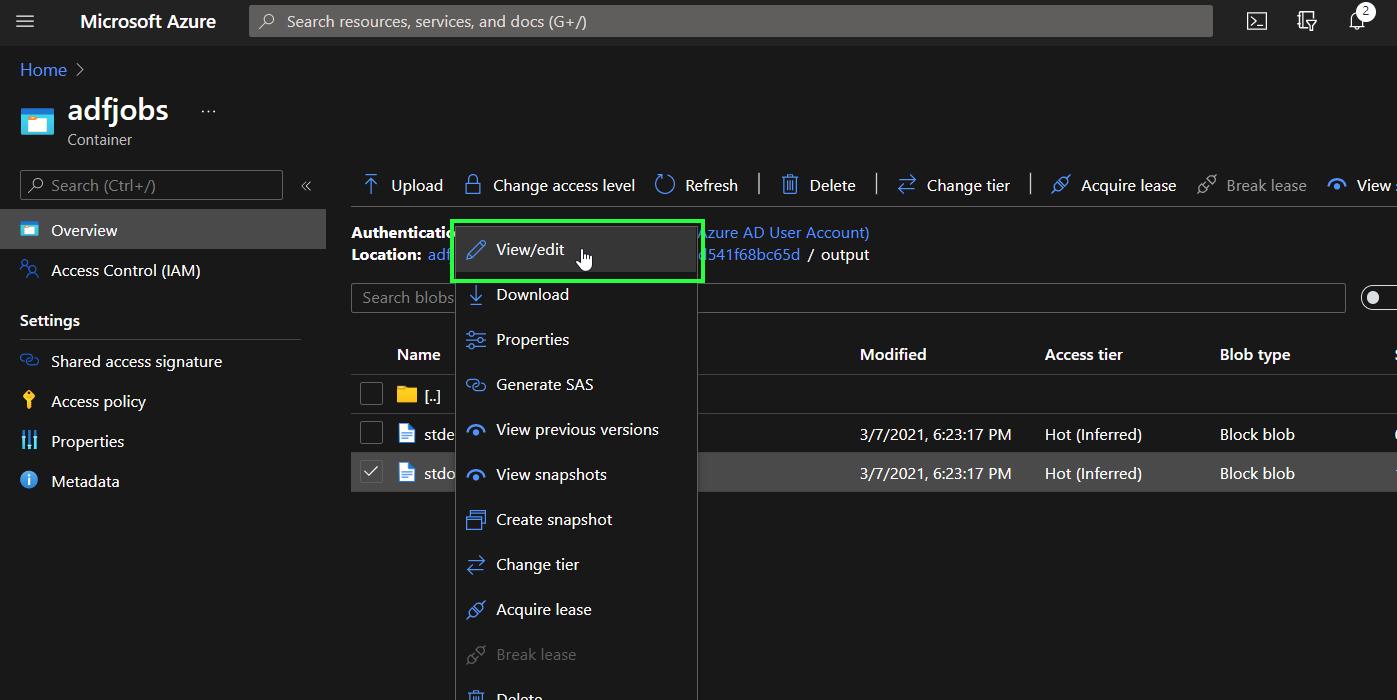
Now that the pipeline is created and tested, it can be connected to triggers and other pipelines, and make part of a bigger orchestration process.






{kind=link}