





The most significant benefit of the project variable feature in dbt is that it enables us to avoid hardcoding information into our queries. Why is this advantageous? Well, consider the following scenario in the context of dbt-bigquery 1.6.4.
example for context
Let’s consider a sample play history of music data from Last FM. We’ll use this data source to create a dimensional table that contains a unique list of tracks.
Now, our objective is to determine what qualifies as a “favorite” track. For our definition, we’ll consider a track as a favorite if it has been played more than 50 times.
One way to approach this is to hardcode this definition directly into the query itself. Here’s an example of how it might look:
if_favorite But what if, at some point, we decide to change the threshold for a “favorite” track to, say, 51 plays?
introduce project variables
If we ever need to update the definition, we would have to modify the query in the model. But what if we’re using this definition in multiple queries? Then making updates becomes tedious and prone to error.
To avoid the hassle of future changes, we use project variables. Simply define your project variable in the dbt_project.yml file:
fav_cut_off in dbt_project.yml Once the variable is defined, we can use the project variable function in the model’s query:
if_favorite using project variables After our dbt run, we can refer to the target/compiled folder to confirm that the query matches our expectations.
types of variables
Project variables can take multiple forms. For example, we can use intergers, strings and dates.
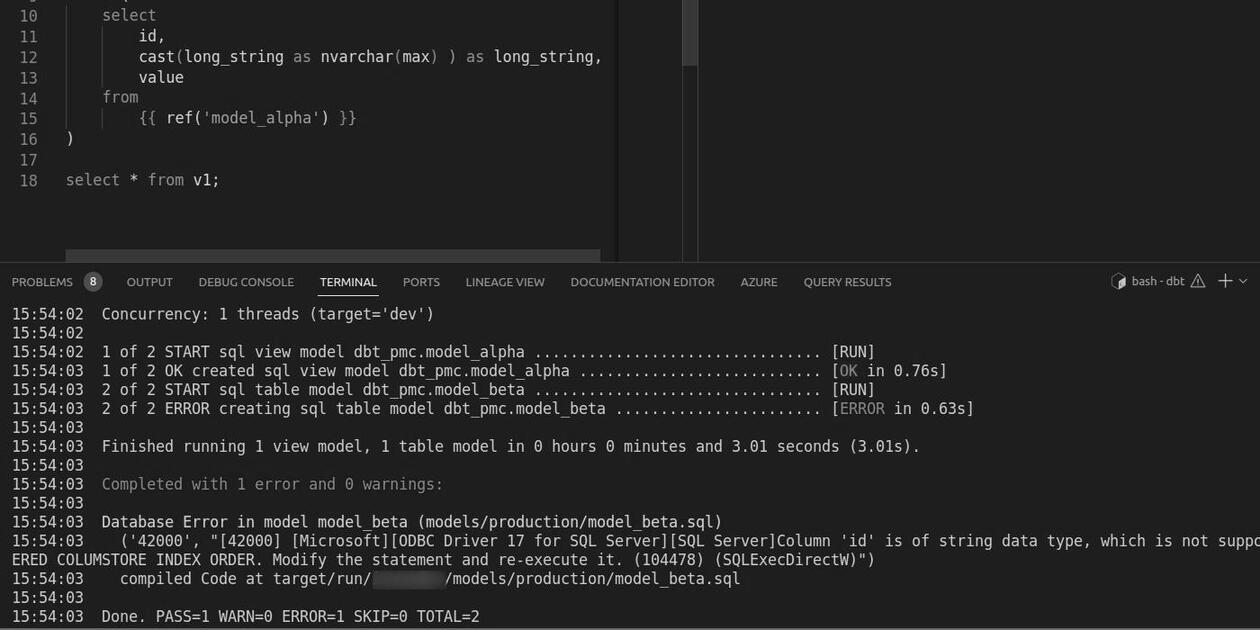
However, it’s important to note that the value will be replaced by the Jinja placeholder. In the case of strings and dates, we still need to use quotations around the Jinja placeholder for the query to be valid.
if_favorite When in doubt, simply run the model containing project variables and check the results in project’s target/compiled folder. Does it look like you expected? Happy querying.





{kind=link}