





When we first encounter the term exposure in the context of data, it doesn’t sound all that appealing. In fact, it’s natural to associate data exposures with the unwanted release of sensitive data. But let’s not judge this feature by its name. In reality, dbt exposures are incredibly practical, and they offer many benefits to dbt developers.
In a nutshell, an exposure is a reference to a data product. This data product can take various forms, such as a dashboard, an application, or a machine learning pipeline. The data product depends on tables, views, and metrics, which are its dependencies, providing the necessary data for its proper functioning.
With exposures, developers can organize and document these dependencies efficiently. They provide an opportunity to explain the intended purpose of these data assets to others working one the data warehouse. Are these tables, views and metrics the backbone of a dashboard, or are they critical for an ML pipeline? How frequently should they be updated, and what’s the downstream value of these data assets?
as YAML files
Creating a dbt exposure is straightforward. We begin by creating a YAML file following the exposure template and its properties, and placing the file in the models/ directory.
Within this YAML file, we set the exposure properties: its name, type, description, and an exposure owner, the person responsible for the data product.
dim_track and fct_play_history as dependents. Using dbt-bigquery 1.6.4 In this YAML file, we also list the exposure’s dependencies, the set of tables, views and/or metrics on which the data product relies. By grouping these data assets into exposures, we can efficiently manage documentation and selection methods for different data products.
as documentation pages
Running the dbt docs generate and dbt docs serve commands generate a dedicated page for exposures. On this page, the dbt developer provides insights into the data product and explains what is expected from its dependencies. For example, we can use tags like ‘hourly’ to indicate that the data assets from an exposure need to be built every hour.
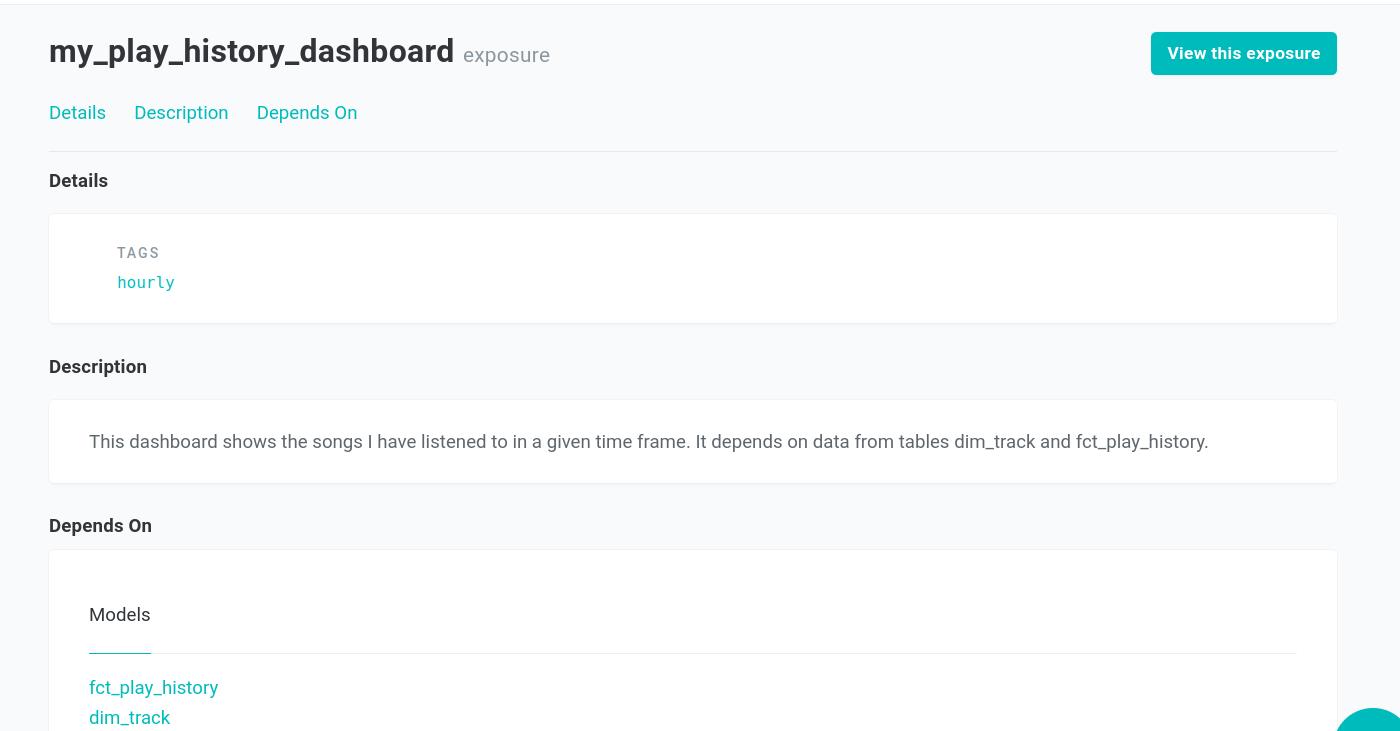
my_play_history_dashboard This documentation page is not only a hub to understand the downstream usage of this group of data assets but also a gateway to access the data product itself. Using the url property in the YAML file, we can specify a link for users to navigate to the data product (see the button View this exposure).
as selector method
Exposures also provide us with an endpoint for running and testing their dependencies. For instance, if our dashboard needs to be updated every hour, we do not have to run a complete dbt build every hour. Instead, we can materialize only those dependencies linked to the dashboard, as specified in the exposure. This approach helps us save time and computing resources.
In the case for exposure my_play_history_dashboard, we use the CLI command:
dbt build --select exposure:my_play_history_dashboard
However, when using an exposure as a selector method, it’s crucial to ensure that the sources the exposure depends on are also kept up to date.
In large dbt projects, manually identifying the sources that feed into the tables and views belonging to the exposure can be time-consuming. In the case for exposure my_play_history_dashboard, we simplify this process in the CLI by using:
dbt ls --select +exposure:my_play_history_dashboard --resource-type source
This command lists all the sources that need updating before building the dependencies associated with the exposure.
In the end, exposures are not as negative as their name might suggest. On the contrary, they are one of the many valuable features dbt has to offer. They should be a part of every dbt project. So go ahead and make use of them. Happy querying.





{kind=link}