





In May 2023, I took the dbt Analytics Engineering Certification Exam. The exam is designed to test one’s ability to “build, test, and maintain models to make data accessible to others” and “use dbt to apply engineering principles to analytics infrastructure.” One of the questions that puzzled me at the time was related to the topic of Directed Acyclic Graph (DAG) execution within multi-thread environments.
The Scenarios
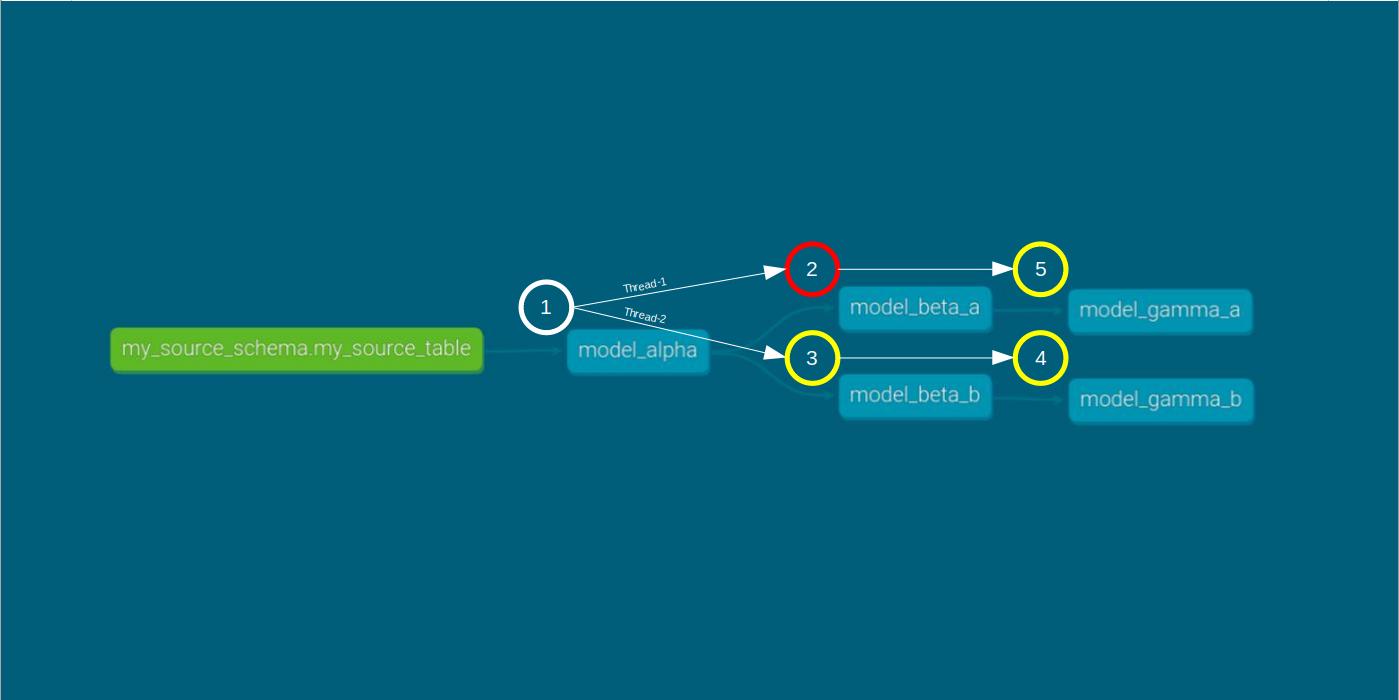
The premise of the question went along the lines of: Picture a DAG with a root node named model_alpha and two directed edges leading to two nodes, model_beta_a and model_beta_b. Each of these nodes connects to its own set of leaf nodes, model_gamma_a and model_gamma_b.
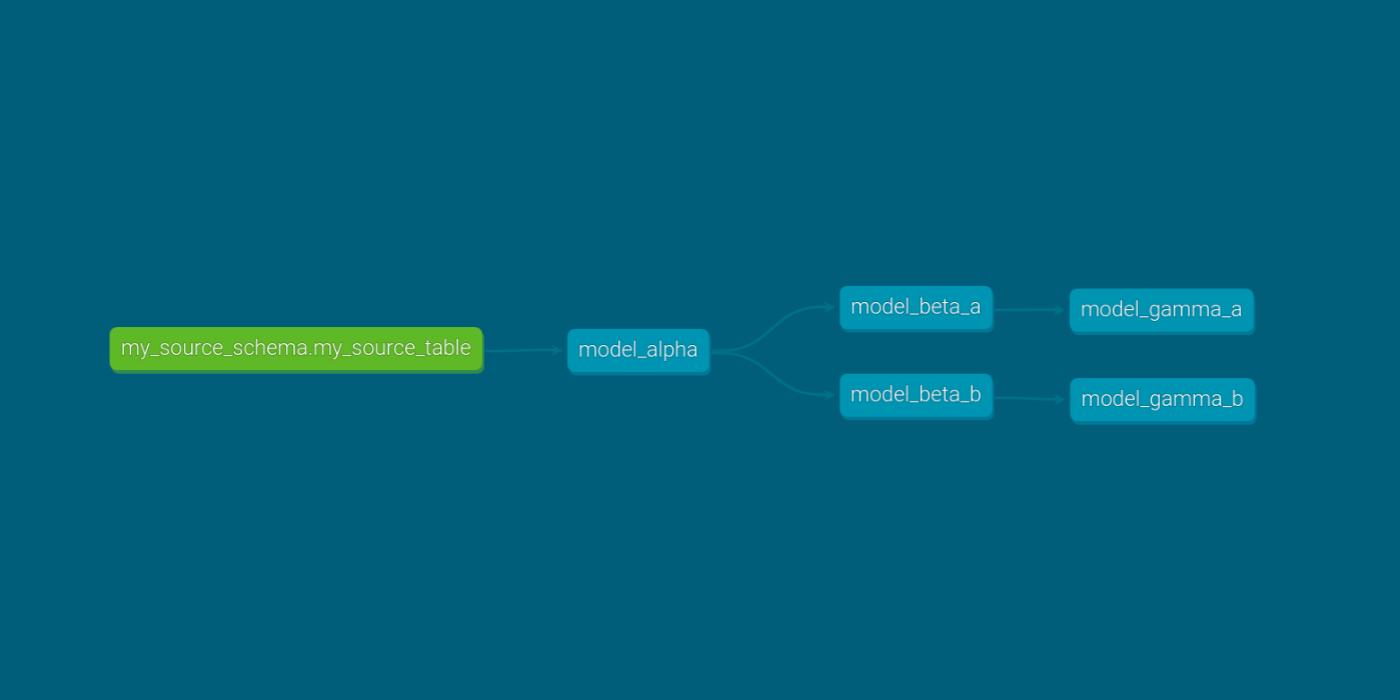
The question posed was: In a scenario where this DAG is run using two threads, with the fail fast argument enabled, what would happen if model_beta_a encounters an error?
To tackle this question, we’ll explore three scenarios using the hypothetical DAG, aiming to observe the differences between running it with a single thread and running it with two threads. The three scenarios are:
- Smooth Run: Executing the DAG without any errors.
- Error Run: Running the DAG where
model_beta_aencounters a division-by-zero error. - Fail-Fast Error Run: Executing the DAG with
model_beta_aencountering a division-by-zero error and the fail-fast argument enabled.
All three scenarios are conducted using dbt core 1.6.1 with the bigquery plugin 1.6.4. For simplicity, all models use materialization of type table.
Some Background
In the context of dbt, a thread represents a path of ordered commands. The number of threads determines the maximum number of paths dbt will concurrently process when executing a DAG. You can specify the number of threads in the profiles.yml file or directly through the dbt command using the --threads argument.
Once the order and the number of paths are determined, dbt proceeds with the compilation and execution of each node. Compilation involves assembling queries and syntax error checking, followed by execution of the compiled query on the target database.
Results and metadata from each dbt run are display in the command-line interface (CLI) and also stored in the target/run_results.json file. This file is updated with each successful run.
Smooth Run
In this scenario, we initiate the DAG run with the command dbt run --threads 1.
dbt run --threads 1 within the smooth run scenario The execution proceeds as expected, with all models being ordered, compiled, and executed in succession. The CLI provides a summary of time results in seconds, while the target folder contains more detailed timing information.
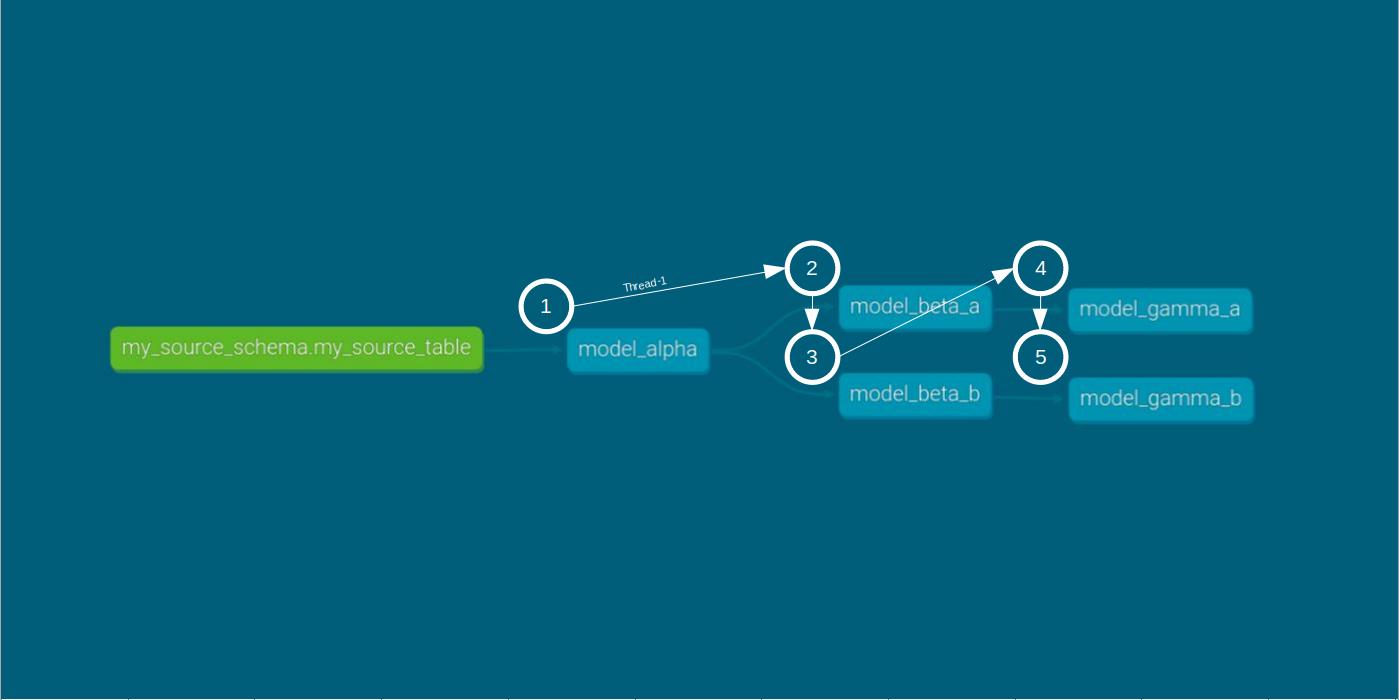
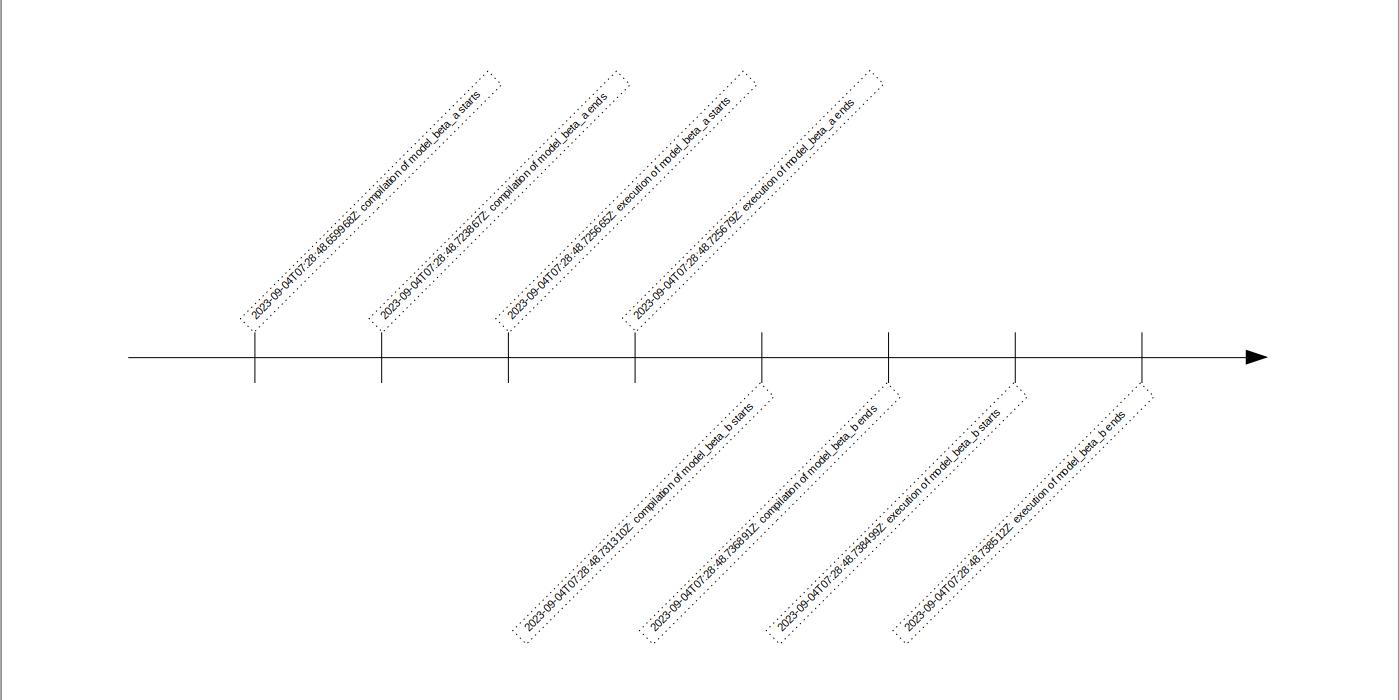
One observation to be made is that model compilation doesn’t begin until the preceding model’s execution is completed.
Now, let’s compare this to the two-thread run with dbt run --threads 2.
dbt run --threads 2 within the smooth run scenario As expected, running the DAG with two threads results in a slightly shorter execution time compared to a single-thread run.
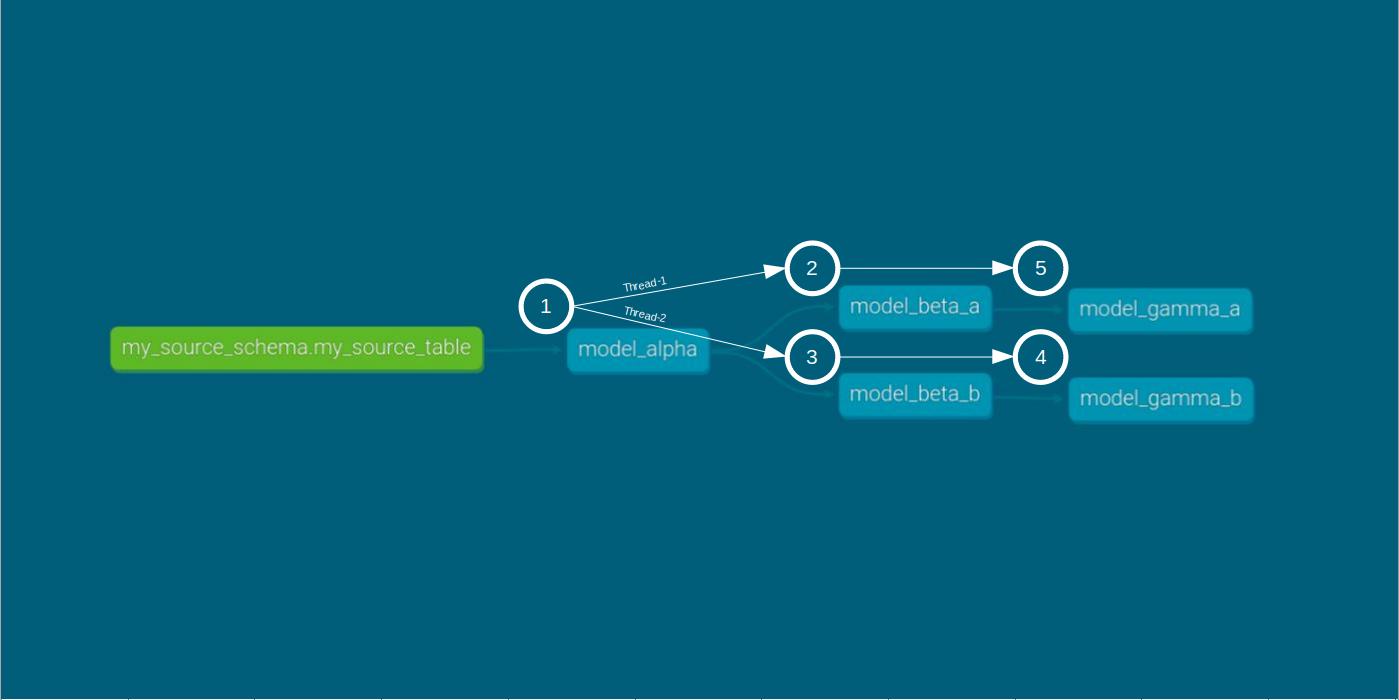
Under the two-thread case, two observations are worth mentioning. Firstly, despite using separate threads and identical queries, both beta models start and end at different times.
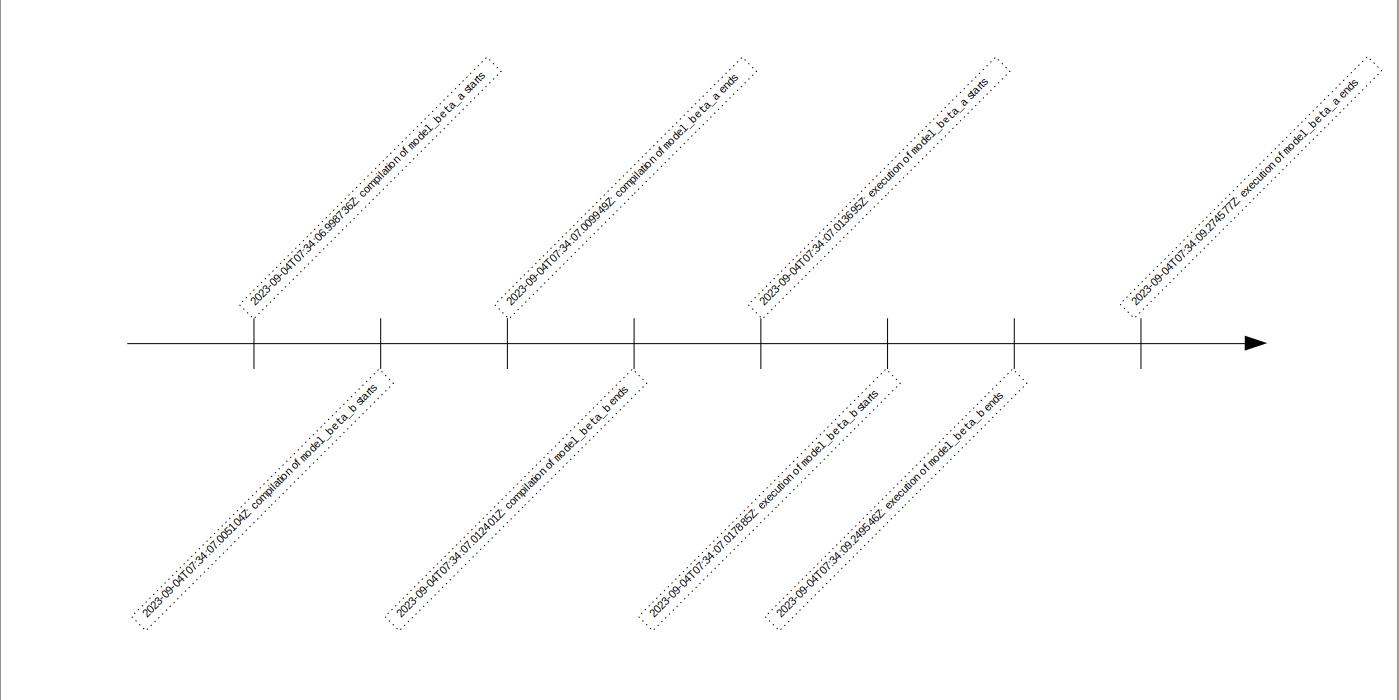
Secondly, unlike the single-thread case, compilation and execution in the two-thread case occur concurrently for the beta models.
Error Run
In this scenario, we intentionally introduce a division-by-zero error in model_beta_a to force an error during the DAG run. We then execute the command dbt run --threads 1.
dbt run --threads 1 within the error run scenario As expected, model_beta_a is compiled and executed but fails to materialize due to the error. As a result of its dependency, model_gamma_a is skipped, and materialization doesn’t occur. Consistent with single-thread execution, compilation of model_beta_b starts after model_beta_a’s execution ends.
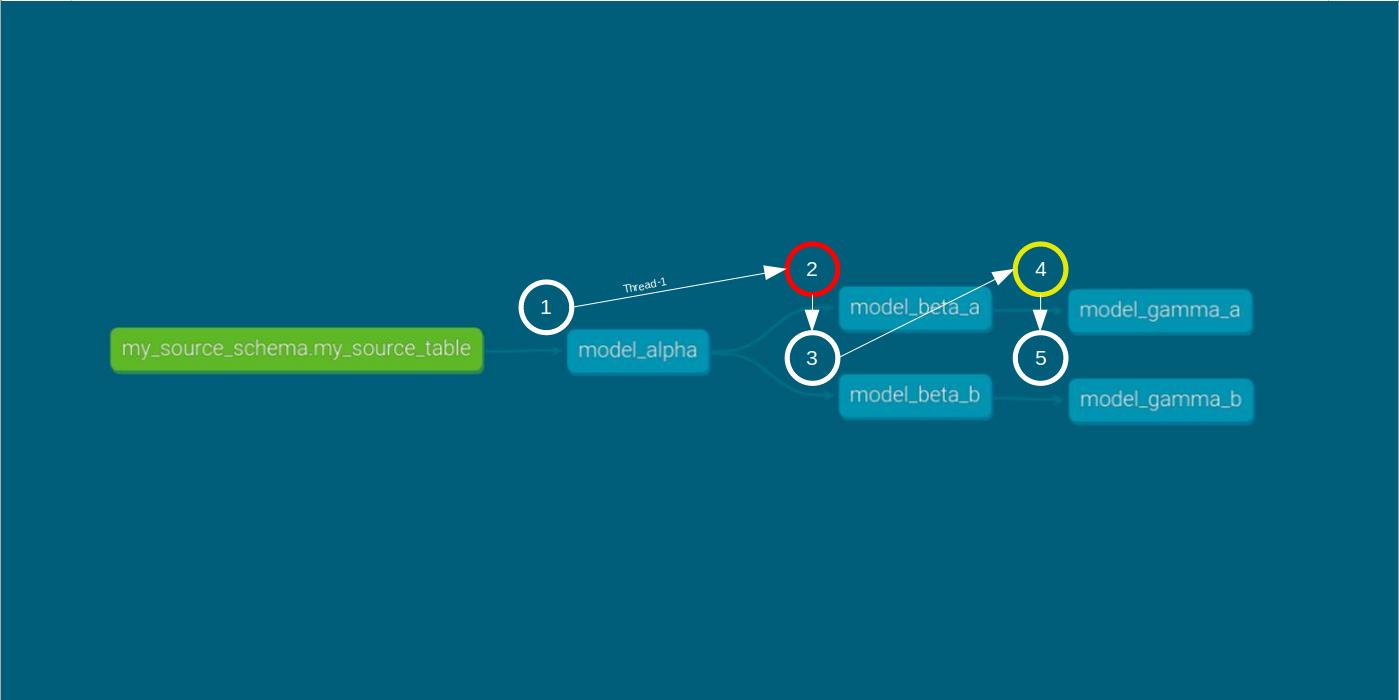
Now, let’s run the same DAG with two threads with the command dbt run --threads 2.
dbt run --threads 2 within the error run scenario Similar to the single-thread case, model_beta_a and model_gamma_a do not materialize in the two-thread case. Also, compilation and execution of the beta models occur concurrently, just as in the smooth run.
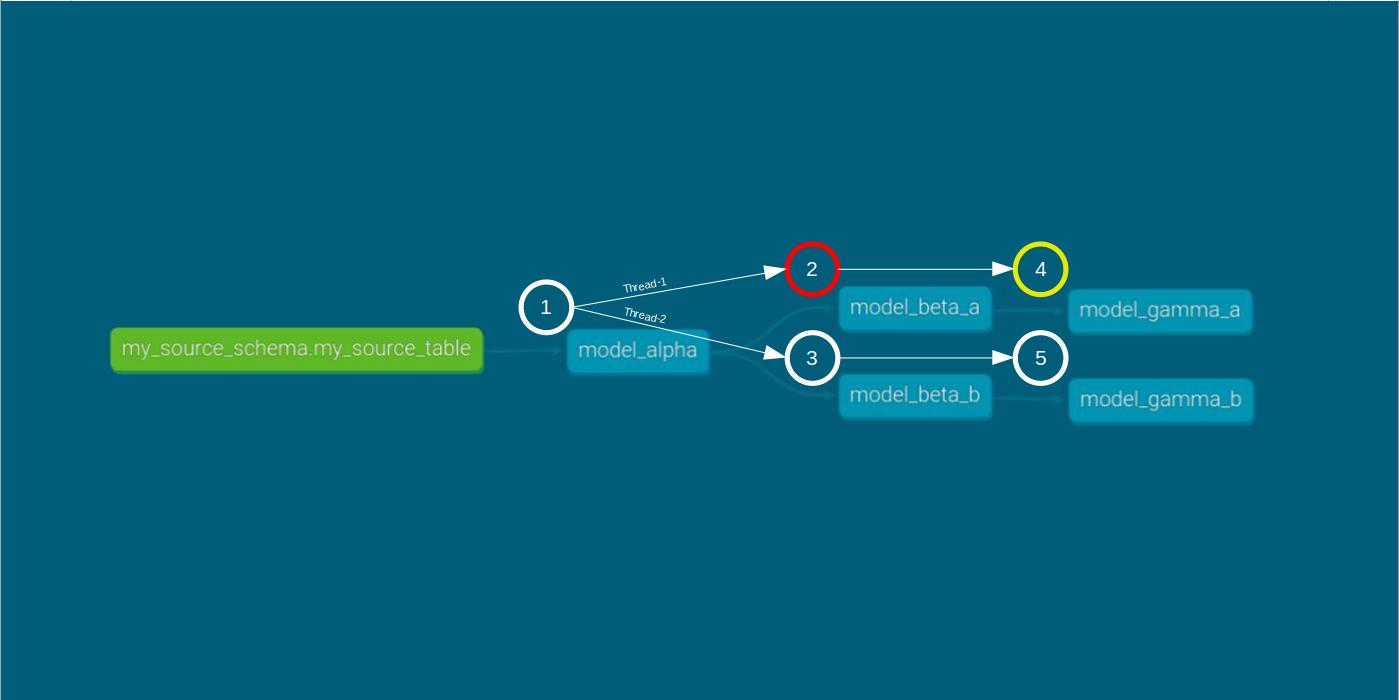
Fail-Fast Error Run
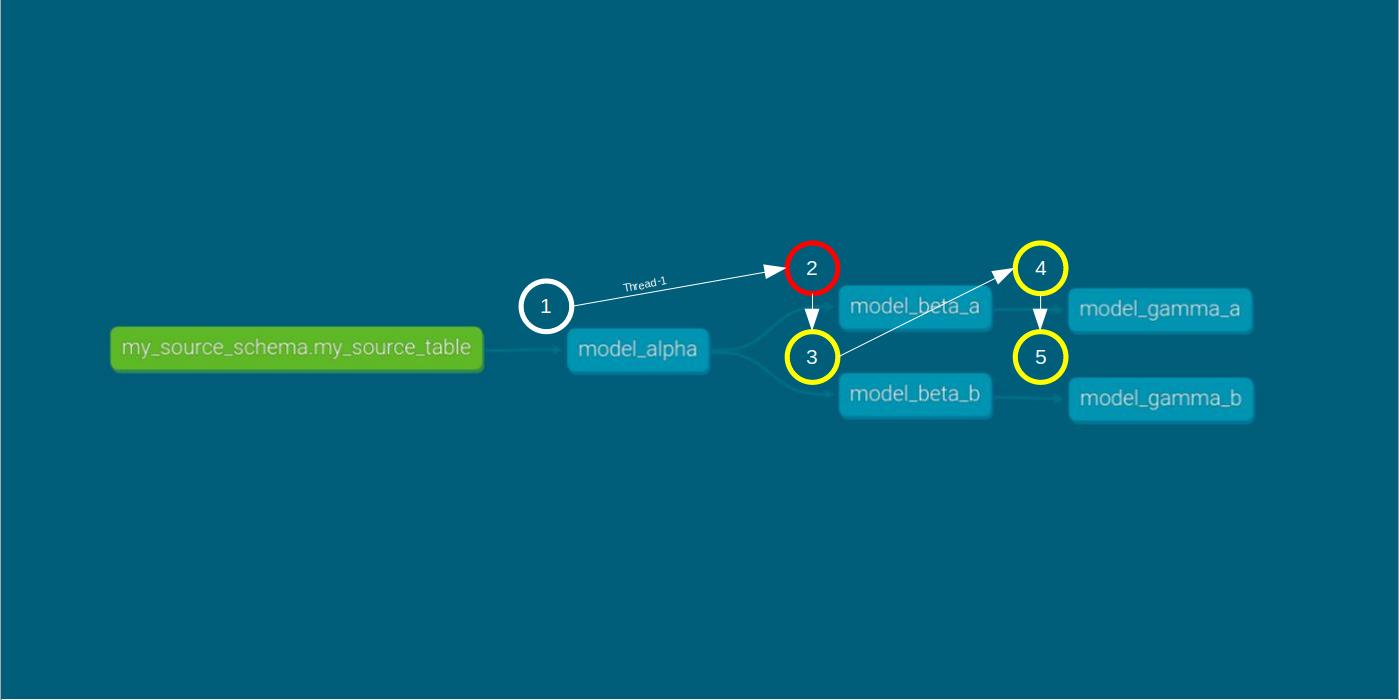
We now introduce the fail-fast argument into our DAG run using the command dbt run --threads 1 --fail-fast.
Our aim is to analyze results from both the CLI and the target folder, specifically focusing on what happens to the remaining models after model_beta_a encounters an error.
dbt run --threads 1 --fail-fast within the fail-fast error run scenario At this point the results become interesting. In the single-thread case, there are discrepancies between the CLI and target results.
As seen in the CLI results, model_beta_a encounters an error and fails to materialize. Surprisingly, despite the single-thread setup, and the fact that models are compiled and executed successively, model_beta_b is given a green light to run.
Then, model_beta_b cannot be stopped, as stated in the CLI: “The bigquery adapter does not support query cancellation.” In the end, the model is materialized.
This story contrasts with the target results. A quick inspection indicates that model_beta_b is skipped “due to fail fast.” Naturally, since the model was skipped, there is no record of compilation and execution times.
Lastly, we run dbt run --threads 2 --fail-fast.
dbt run --threads 2 --fail-fast within the fail-fast error run scenario Similar to the single-thread case, the CLI reports that model_beta_b is triggered and materialized. Yet, once again, the target results suggest this model was skipped.
Conclusion
In summary, we see that the execution of a DAG respects dependencies. If an upstream model fails, downstream models are skipped, regardless of the number of threads. However, the execution of a DAG does not consistently respect the fail fast argument.
So, what is the answer to the original question? The answer is, it depends.
In theory, models running in parallel in a two-thread environment should be canceled and marked as skipped.
Yet, in practice, whether a model running in parallel is run and materialized depends on the dbt adapter’s support for query cancelation. In the case of the BigQuery adapter, it does not seem to support query cancelation. Thus models running in parallel could still be materialized.






{kind=link}